2024年10月28日,结束了一个Python基础语法的学习,这篇教程的话就是从数据存储开始,到哪里还没定。
本教程的话是基于B站黑马程序员的教程视频编写过来,就相当于我的读书笔记,欢迎大家去看他的视频。【黑马程序员python教程,8天python从入门到精通,学python看这套就够了】https://www.bilibili.com/video/BV1qW4y1a7fU
一、数据容器 – 列表
1、定义
数据类型是什么?数据类型就是一个可以存储多个元素的数据类型,相当于C语言的数组。Python存储的数据有哪些类型?如:list(列表)、tuple(元组)、str(字符串)、set(集合)、dict(字典)。
接下来将给大家解释下列表的定义方式:
keyword_list = ['真境','博客','网站']
print(keyword_list)
print(type(keyword_list))输入内容如下:
['真境', '博客', '网站']
<class 'list'>当然你的数据容器也可以放其他的东西:
keyword_list2 = ['Hello', 111, True]
print(keyword_list2)
print(type(keyword_list2))当然列表里面放列表都可以:
keyword_list3 = [[1,2,3],[4,5,6]]
print(keyword_list3)
print(type(keyword_list3))他们的最终结果都是list类型的东西
2、列表的索引
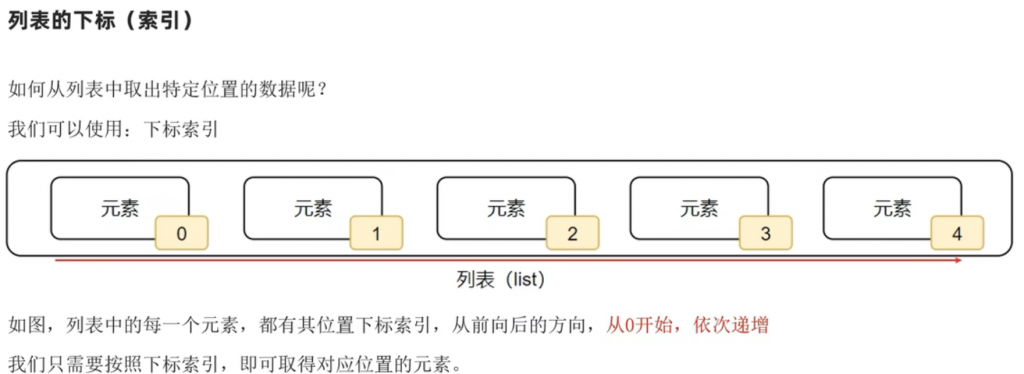
列表的索引有什么好处,就是可以直接提取出列表中第几位的内容,比如说:
keyword_list = ['真境','博客','网站']
print(keyword_list)
print(type(keyword_list))
print(keyword_list[0])输出的内容就是:
['真境', '博客', '网站']
<class 'list'>
真境我们列表的索取第一位就是0,因此我们提取出了 真境 。当然我们也可以反向索引,从右边开始数,就是-1,-2这样数下去。诶,那我们刚刚有一个嵌套列表,他又要怎么获取其中的数据呢?接下来看示例:
keyword_list3 = [[1,2,3],[4,5,6]]
print(keyword_list3)
print(type(keyword_list3))
print(keyword_list3[0][1])在 print(keyword_list3[0][1]) 中 我们提取了 keyword_list3 数据中的第一个内层数列,并且提取了第二个数字,也就是 2
3、列表的常用操作方法
①数据的提取
那除了输出数据,那我们也要检索一下数据在什么地方,在数列的第几位,接下来看以下例子:
keyword_list = ['list','zhenjingyo','blog','python']
index = keyword_list.index("zhenjingyo")
print(f"你找的zhenjingyo在列表的第{index+1}位")这样的话我们可以快捷的读取到我们检索的内容在哪。
②修改列表的值
如果你想要修改列表中的一个数据的值,可以这么做:
keyword_list = ['list','zhenjingyo','blog','python']
index = keyword_list.index("zhenjingyo")
print(f"你找的zhenjingyo在列表的第{index+1}位")
keyword_list[0] = 'all'
print(keyword_list[0])这样的话就可以把列表中的第一个数据更改成all了。
③列表插入元素
我们可以通过列表的insert来进行插入:
keyword_list = ['list','zhenjingyo','blog','python']
index = keyword_list.index("zhenjingyo")
print(f"你找的zhenjingyo在列表的第{index+1}位")
keyword_list.insert(1,'zhenjingooo')
print(keyword_list)这样的话 zhenjingooo就可以插入第二位了。
④追加元素
不止中间插入元素,也可以在数列的尾部来进行插入,我们可以用appear来进行插入:
keyword_list = ['list','zhenjingyo','blog','python']
index = keyword_list.index("zhenjingyo")
print(f"你找的zhenjingyo在列表的第{index+1}位")
keyword_list.append(4)
print(keyword_list)当然也可以插入很多:
keyword_list.append([1,2,3,4])⑤删除元素
有多种方式,第一个就是比较简单的一个删除:
del keyword_list[0]
print(keyword_list)就直接删除掉数列的第一个内容。第二个方法就是利用pop来提出列表的内容:
elements = keyword_list.pop(0)
print(f"提出的内容是{elements},剩下还有{keyword_list}")这样的话就可以提出第一位的内容。也可以用remove元素来进行删除:
keyword_list.remove('blog')
print(keyword_list)他可以删除指定的内容,也可以删除第几位的东西。也可以直接清空列表的内容:
keyword_list.clear()
print(keyword_list)⑥列表的计数
我们可以通过count来计算说一个数列中有多少个xxx,比如说:
count = keyword_list.count('python')
print(f"列表中还有{count}个python")这样的话我们就可以数到底有几个python了。当然也可以直接数整个列表有一个元素:
print(len(keyword_list))好了 以下是黑马程序员的一个介绍总览:
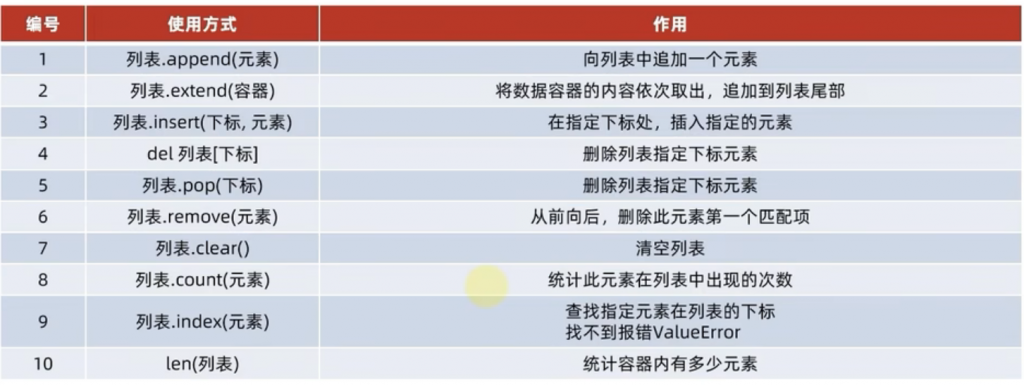
4、列表的遍历
Python中列表的遍历其实和C语言中的数组的遍历是同一个道理,都是通过for while 等循环语句来完成的。示例代码如下:
my_list = ['list','test','zhenjing']
index = 0
while index < len(my_list):
print(my_list[index])
index += 1我们先设置索引为 0,因为遍历数组从第一个数开始,当然你倒着来也行,然后我们自定一个循环函数,通过len函数来判断列表的长度来取决是否循环,后print输出列表,注意在结束的时候几个给索引+1,否则循环将无限进行。当然通过 for 循环的话也能写出列表的遍历:
for elements in my_list:
print(elements)
按照黑马程序员的说法,就是将 my_list 中的元素赋值在了 element 上。
①题目 – 输出列表中的偶数和奇数(简单)
就是给你来个列表 里面填上了 1 2 3 4 5 6 7 8,需要做的就是输出其中的偶数和奇数。示例如下:
my_list = [1,2,3,4,5,6,7,8,9]
index = 1
while index < len(my_list):
print(my_list[index])
index += 2这是我的代码,其实看起来都很简单 当 index = 1的时候就是输出偶数 0 的时候就是输出奇数。
②题目 2 取偶数(略难)

其实说难不倒哪里去,都是我们学过的东西,既然放出来了那就公示下答案吧:
my_list = [1,2,3,4,5,6,7,8,9]
oushu_list = []
def printthing():
index = 1
while index < len(my_list):
if my_list[index] % 2 == 0:
oushu_list.append(my_list[index])
index += 1;
printthing()
print(f"当前数组为{my_list},其中的偶数为{oushu_list}",end='')for的我就懒得写了 别打我233
二、数据容器 – 元组

所以元组和列表的差别就是在一个可修改不可修改的差别上。接下来我们可以看元组的例子:
t1 = (1,2,3,4,5)
print(type(t1))输出的内容:
<class 'tuple'>和列表不同是是元组的符号是括号,而列表的是中括号。同时元组可以和列表一样嵌套:
t2 = ((1,2,3),(4,5,6))也可以通过下标索引来取出内容:
t2 = ((1,2,3),(4,5,6))
num = t2[1][2]
print(num)然后接下来就是关于元组的一个相关操作:

示例代码:
t3 = ("真境","博客")
put = t3.index("真境")
print(f"数据 真境 的内容下标索引在 {put}")
count = t3.count("真境")
print(f"数据中一共有{count}个真境")
len = len(t3)
print(f"数据的长度是{len}")内容都不多解释,基本和列表都有一定的相似。也可以进行元组的遍历:
index = 0
while index <len:
print(f"元组的列表有:{t3[index]}")
index += 1当然for循环遍历也是可以的:
for elements in t3:
print(elements)虽然说元组中不能修改内容,但是在元组中嵌入列表的话是可以修改内容的:
t4 = (1,2,3,4,["真境","yo"])
print(t4)
t4[4][1] = "真境的博客"
t4[4][0] = "zhenjing"
print(f"最终的修改内容为:{t4}")注意的是修改内容的索引顺序还是要遵循元组的顺序来的。
三、数据容器 – 字符串
1、简单介绍 – 定义
没错字符串也是可以形成一个数据容器的,其中的用法也是和元组和列表差不多的。接下来是一个索引内容的用法。接下来就展示下标的索引取值和index的用法:
my_str = "zhenjing blog is a blog"
print(my_str[0])
value = my_str.index("is")
print(f"is在{value}")输出的内容就是:
z
is在14和上方的 元组和列表 都是同一个的用法,这边不读阐述。
2、replace用法
replace就是一个替换字符串组的一个函数,使用方法如下:
new_my_str = my_str.replace("zhenjing","zhenjingyo")
print(f"替换前的内容为:{my_str},替换后的内容是:{new_my_str}")
通过PyCharm显示的内容,就是将zhenjing换成zhenjingyo。
3、split方法
split 就是一个切割的函数,将字符串组的内容切割出来,那么如何使用?请看示例:
my_str = "zhenjing blog is a blog"
split_my_str = my_str.split(" ")
print(f"通过切割后的结果是{split_my_str},类型是{type(split_my_str)}")输出的内容为:
通过切割后的结果是['zhenjing', 'blog', 'is', 'a', 'blog'],类型是<class 'list'>切割的内容以什么为主?以空格为主,那就是将我们空格分开,形成新的列表,但是你会发现真的切割后的内容还真的是列表哦。
4、strip方法

这是黑马程序员的一个定义方式。来我们看示例代码:
strip_my_str = " 123zhenjing "
print(strip_my_str.strip())
strip_my_str = "123zhenjing"
print(strip_my_str.strip("123"))输出内容:
123zhenjing
zhenjing以上面黑马程序员的截图来作为参考和解释。当然要注意的是 他去掉的不是字符串123而是字符 1、2、3,也就是说如果我需要删除的字符串组中有321 也要一起去掉。
最后的话 和前面元组和列表一样 都可以进行使用 count 计数,也可以用 len 来计算长度。接下来偷一下黑马程序员的汇总:
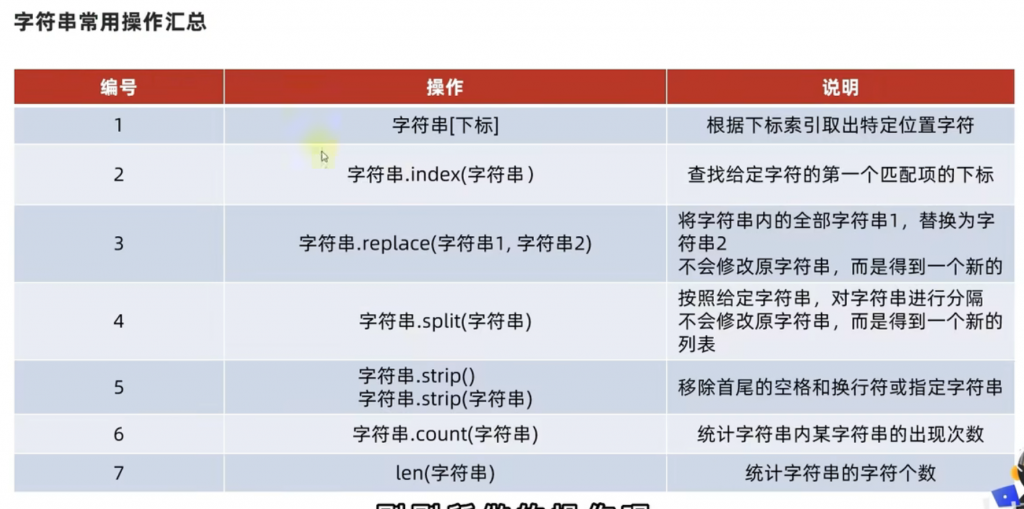

①题目-分割字符串
直接引用黑马程序员的题目内容:
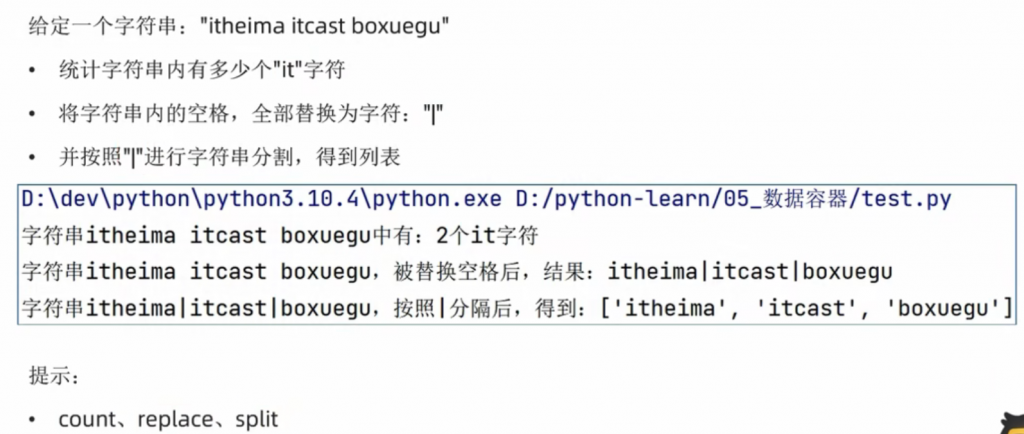
直接放答案:
my_str = "itheima itcast boxuegu"
print(f"it一共有{my_str.count("it")}个")
new_my_str = my_str.replace(" ","|")
print(f"替换后的结果是:{new_my_str}")
new_my_str1 = new_my_str.split("|")
print(f"分割后的结果是;{new_my_str1}")四、序列
1、定义
序列是什么?按照黑马程序员的说法就是:
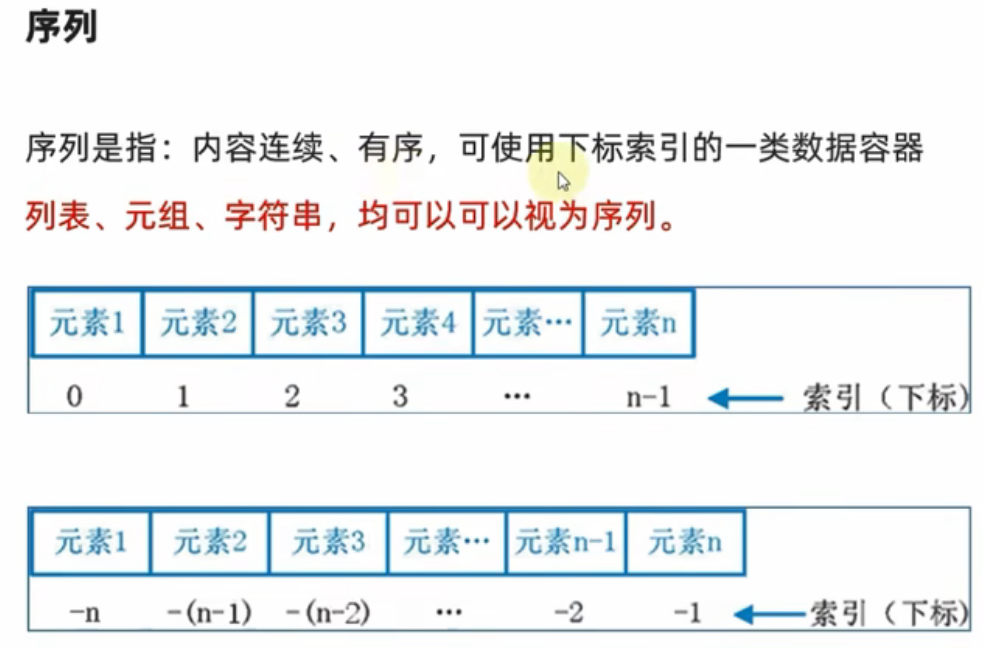
2、序列的切片
什么是序列?序列就是我们前面所说的列表、元组、字符串组那些 他们都是序列,那序列的切片是什么?请看黑马程序员的解释:

接下来我们看示例代码:
list = [1,2,3,4,5,6,7,8,9]
print(list[1:4])
t1 = (1,2,3,4,5)
my_str = "123456789"
print(my_str[::-1])
list2 = [1,2,3,4,5,6,7,8]
print(list2[3:1:-1])
t2 = (1,2,3,4,5,6,7,8,9)
print(t2[::-2])输出的内容是:
[2, 3, 4]
987654321
[4, 3]
(9, 7, 5, 3, 1)解释的话大概率不需要解释,相信大家都能懂。然后黑马程序员这里也有一个题目,就放这边了 小问题,没写下去的劲头了。

五、集合
1、集合的定义
集合也是属于一种序列,他和前面的元组列表字符串都是同一类东西。那我们为什么要学集合呢?看黑马程序员的说法。

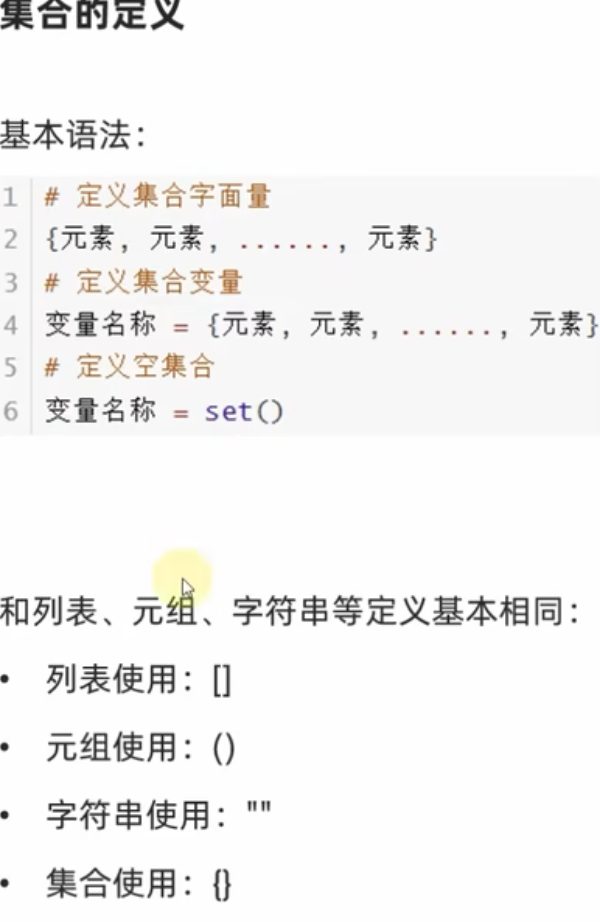
示例代码:
my_set = {1,2,3,4,5,6,7,8}
print(my_set)
print(type(my_set))输出的内容:
{1, 2, 3, 4, 5, 6, 7, 8}
<class 'set'>可以看出来 集合就是个set。
2、添加元素
为序列添加一个元素的话需要用add函数,使用办法如示例所示:
my_set.add("zhenjing")
print(my_set)输出的内容:
{1, 2, 3, 4, 5, 6, 7, 8, 'zhenjing'}但是,大家还记得我们前面说的,序列不支持去重吗?因此如果说我再添加一个1实际上还是一样的结果。
3、删除元素
删除序列中的某可以元素可以用remove函数:
my_set.remove("zhenjing")
print(my_set)这样的话就把我刚刚加的zhenjing给删除了。
4、pop函数
pop函数有什么用?他可以用作于随机抽取一个元素,因此集合可以做一个抽奖系统(X),来看示例代码:
elements = my_set.pop()
print(elements)5、清空集合
直接清空集合中的所有元素:
my_set.clear()
print(my_set)这样啥东西都没有了咯。
6、集合的差集
集合的差集就类似于高中的补集一样,两个集合中来寻找两个没有一样的元素,查看示例代码:
set = {1,2,3}
set1 = {1,3,5,6}
set3 = set1.difference(set)
print(set3)这样输出的内容就是 5 和 6

7、消除差集
直接删除两个集合间的差集,示例代码:
set = {1,2,3}
set1 = {1,3,5,6}
set3 = set1.difference_update(set)
print(set)
print(set1)
8、集合的合并
这样的话可以将两个集合集合成一个集合,只不过说相同的元素的话不会同步。示例代码:
set = {1,2,3}
set1 = {1,3,5,6}
print(set1.union(set))输出的内容:
{1, 2, 3, 5, 6}9、关于集合的补充
同样的,也可以通过我们上面所说的len 来计算集合的长度。也可以进行集合的遍历,然后接下来看黑马程序员留下的总结:
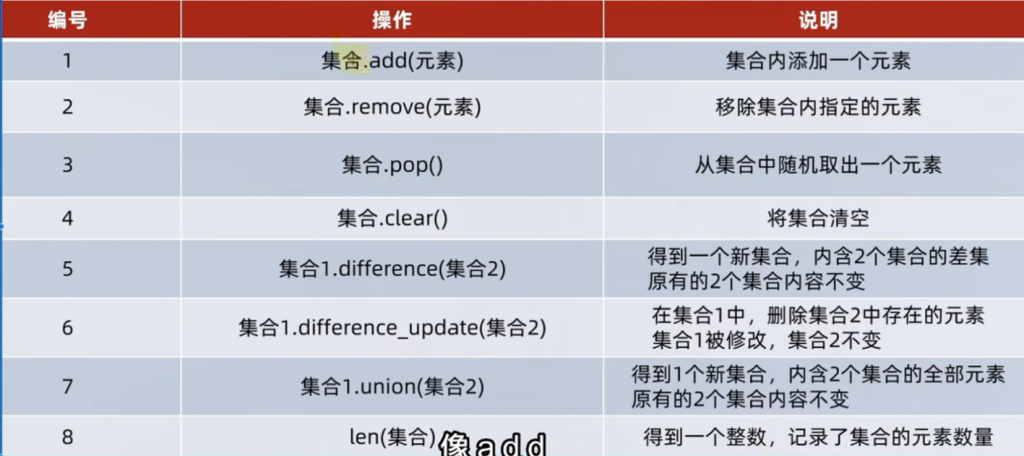
①题目

答案:
my_list = ['黑马程序员','传智播客','黑马程序员','传智播客','itheima','itcast','itheima','itcast','best']
set(my_list)
my_set = set()
for elements in my_list:
my_set.add(elements)
print(my_set)我没写得非常详细,但是基本的内容都写出来了,不多解释。
六、字典
1、定义
字典是什么?字典就差不多和我们生活中遇到的那本字典一样,他存在着 Key 值 和 Value 值,一个Key值都对应着一个Value值,他也可以和数据容器一样,类似于集合,接下来看个例子:
dict = {"真境":100,"zhenjingyo":99}
print(dict)
print(type(dict))输入的内容:
{'真境': 100, 'zhenjingyo': 99}
<class 'dict'>字典有一些地方还是和集合相似的,比如说不能用下标来进行索引,但是的话,他可以通过 Key 值来寻找 Value 值。示例如下:
score = dict["真境"]
print(score)这样的话 就可以索引出Key的Value值了。当然的话字典的话也是可以嵌套的,套娃,什么都能套娃,接下来看一个示例内容:
qiantao_dict = {
"真境": {
"语文":100,
"数学":200,
},"zhenjing": {
"语文":100,
"数学":200,
}
}
print(qiantao_dict["zhenjing"]["语文"])这样的话可以同时存储每个人的各科成绩,通过下面的print也能输出指定的成绩。
2、字典的常用操作
①增加元素
字典的内容都是可以添加内容的,示例代码:
my_dict = {"1":100,"2":99,"3":98}
my_dict["4"] = 97
print(my_dict)这样的话我们就往 my_dict 字典中加入了个Key为4,Value值为97的内容。
②修改元素
元素的话其实和集合一样,都不允许元素相同的,因此说我们可以通过覆盖的方式来修改元素内容:
my_dict = {"1":100,"2":99,"3":98}
my_dict["4"] = 97
print(my_dict)
my_dict["4"] = 99
print(my_dict)这样的话就直接通过覆盖的形式 将Key为4的Value从97改到了99
③删除元素
删除元素的话和集合的pop有点冲突,在集合中pop是作为随机抽取一个内容,而在字典中就是删除:
score = my_dict.pop("4")
print(my_dict)这样的话就可以把我们刚刚添加的Key 4 给删除掉了。
④清空元素
和之前的一样 都是使用clear函数来进行清空:
my_dict.clear()
print(my_dict)⑤元素遍历
字典的元素也可以遍历,通过下面的示例代码,可以将Key和Value轮着输出一遍:
for i in my_dict:
print(i)
print(my_dict[i])⑥元素数数+总结
len的话还是一样的,可以计算元素的长度:
print(len(my_dict))然后接下来看黑马程序员的总结:
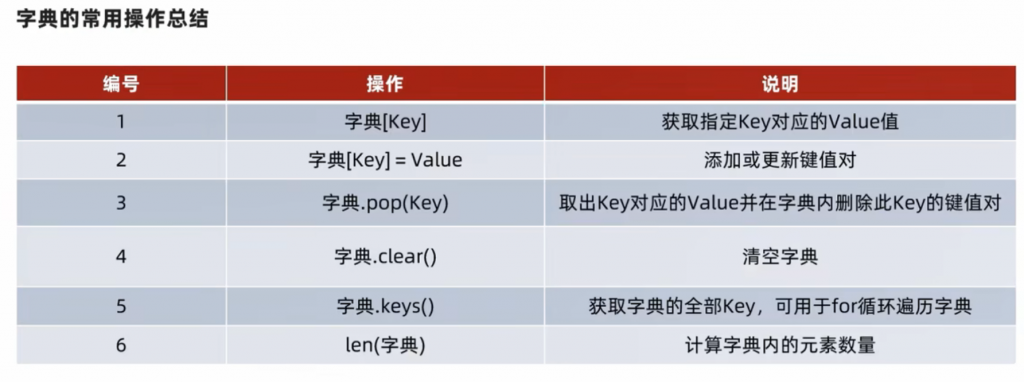
⑦题目 – 升职加薪
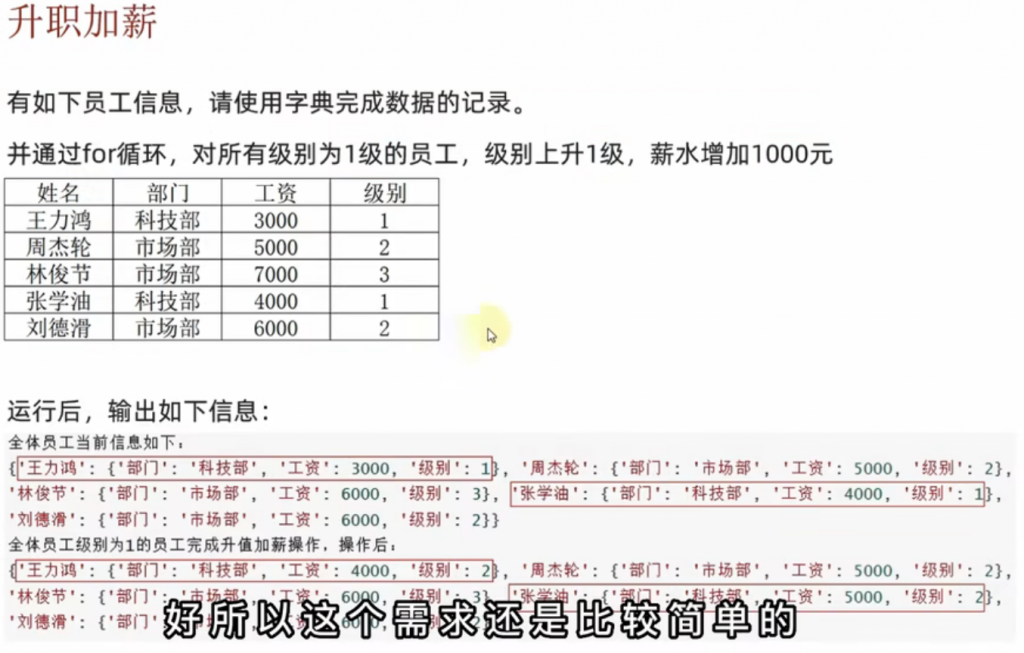
参考答案:
dict = {
"王力鸿":{
"部门":"科技部",
"工资":3000,
"级别":1,
},"周杰轮":{
"部门":"市场部",
"工资":5000,
"级别":2,
},"林俊节":{
"部门":"市场部",
"工资":7000,
"级别":3,
},"张学油":{
"部门": "科技部",
"工资": 4000,
"级别": 1,
},"刘德华":{
"部门":"市场部",
"工资":6000,
"级别":2,
}
}
for i in dict:
if dict[i]["级别"] == 1:
dict[i]["工资"] += 1000
dict[i]["级别"] += 1
print(dict)
七、数据容器的最终总结
1、特点
我又继续把黑马程序员的总结拿走了:

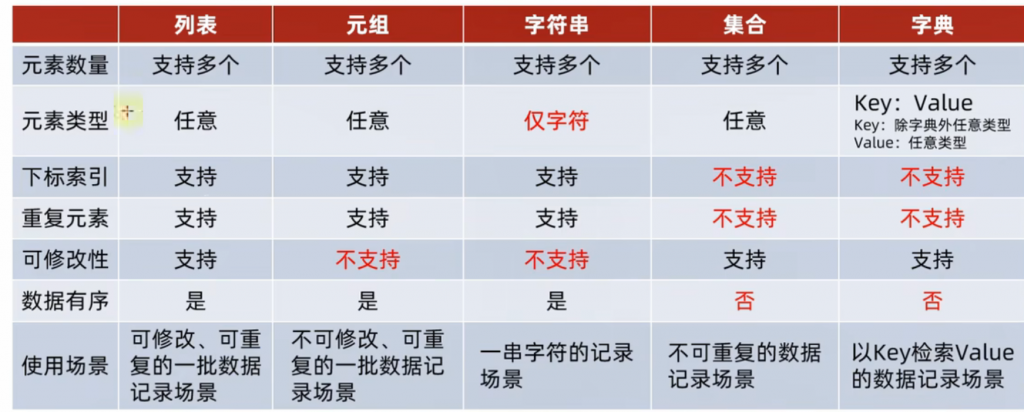

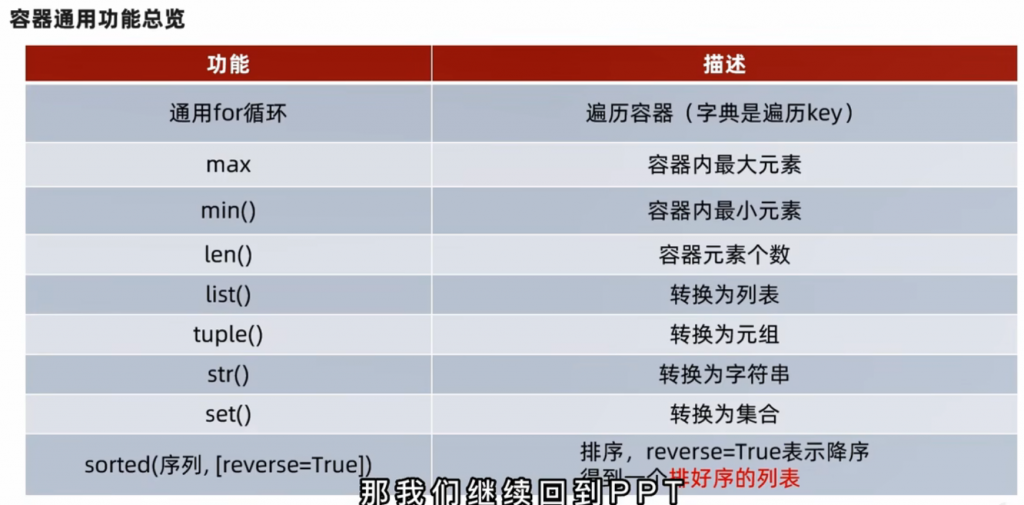
2、通用操作
①通用统计功能

接下来我放出示例代码来展示max函数:
mylist = [1,2,3]
mytuple = (1,2,3,4,5)
mystr = "zhenjing"
print(max(mytuple))
print(max(mylist))
print(max(mystr))输出内容:
5
3
z②通用转换

③通用排序

关于这个排序的功能 我们前面好像没有讲过,接下来就展示代码给大家看:
my_untidy_list = [2,5,1,3,4]
my_untidy_tuple = (2,3,1,4,5)
my_untidy_str = "zhenjing"
print(sorted(my_untidy_list))
print(sorted(my_untidy_tuple))
print(sorted(my_untidy_str))输出的内容是:
[1, 2, 3, 4, 5]
[1, 2, 3, 4, 5]
['e', 'g', 'h', 'i', 'j', 'n', 'n', 'z']这样的话就可以按顺序进行排序了。如果你需要降序的话就用 reverse=True,示例:
print(sorted(my_untidy_str,reverse=True))接下来就是一个总体的概况总结:
七、函数的返回值(进阶)
1、多个返回值
我们上次说过,在自定义函数的时候可以使用 return 函数来定义一个返回值,但是有没有想过可以一次性设置多个返回值呢?接下来看示例代码:
def test():
return 1,2,3
x,y,z = test()
print(x)
print(y)
print(z)在这个示例代码中,我们自定义了一个叫test的变量,里面什么都没有就一个return函数,他返回了三个值 1 2 3,然后我们设置了3个变量分别是 xyz,都将 1 2 3 三个数字都复制在了三个变量中,因此 x = 1,y = 2,z = 3。同时的话函数的返回值可以是字符串,也可以是其他类型的形式:
def test():
return "Hello",2,True
x,y,z = test()
print(x)
print(y)
print(z)2、函数参数种类
①关键字参数

就是我们之前说过,传入参数的话是一个一个对应的,这样的话比较死,接下来为大家介绍了是关键字参数,如何使用呢?看示例代码:
def info(name,age):
print(f"{name}的年龄是:{age}")
info(age=20,name="张三")这样的话就不用一个顺序一个顺序的输入了,而是对应的“键=值”的形式来传递参数。这样的话可以使函数更加清晰、容易使用。也不需要顺序输入了。
②缺省函数
缺省函数是什么?当一个关键字参数或者位置参数没有进行传入参数的话,那他的作用就是提供一个默认的参数值。示例代码:
def userinfo(name,age=18):
print(f"{name}的年龄是{age}")
userinfo(name="张三")示例代码中,传入参数只有一个 那就是name,如果说我没有特地的去传入age函数的话,那么张三的默认年龄就是18岁。那如果说我有传递参数,比如说张三19岁,那么19岁的优先级是要比18岁还高的。
但是注意的是:默认值只能存在后面,比如说age必须在name后面
③不定长参数
不定长参数是什么?他用作于不确定参数数量的时候。

a)位置不定长
位置不定长的形式参数会作为元组存在,接受不定长数量的参数传入。
def test(*args):
print(f"类型是:{type(args)},里面存储的内容是:{args}")
test(1,2,3,4,"man")说好用还是挺好用的,如果说用在正确的地方的话确实好用,这样的话就可以把我们刚刚输入的全部元素作为元组来存储了。
b) 关键字不定长
和前面差不多的原理,就是元组替换成了字典,接下来看示例代码:
def test1(**kwargs):
print(f"类型是:{type(kwargs)},里面存储的内容是:{kwargs}")
test1(name="123",age="18")不过注意的是 我们必须遵循“键=值”的形式进行存储,也就是Key=value。
总结:(来自黑马程序员)

3、函数作为参数传递
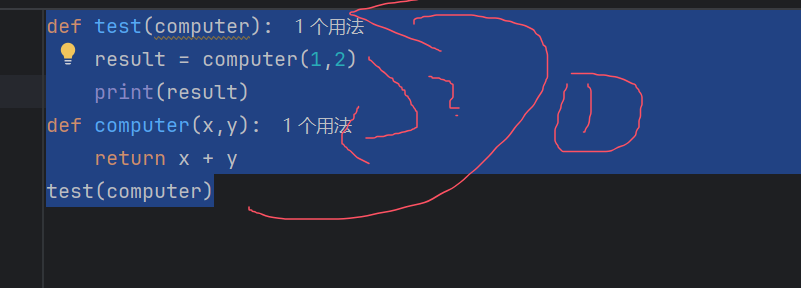
函数的话可以作为一个传参函数进行传递(又是套娃)看示例代码:
def test(computer):
result = computer(1,2)
print(result)
def computer(x,y):
return x + y
test(computer)运作原理:

4、lambda匿名参数

如何使用匿名参数呢?

接下来看示例代码:
def func(computer):
result = computer(1,2)
print(result)
func(lambda x,y:x+y)示例代码的话就是代替了我们上面的函数作为参数传递的例子。就是通过匿名函数来传入函数说要做什么操作。
注意的是:匿名函数的话只允许只有一行函数体。虽然说不能写多行,但是他确实给我们代码优化了很多
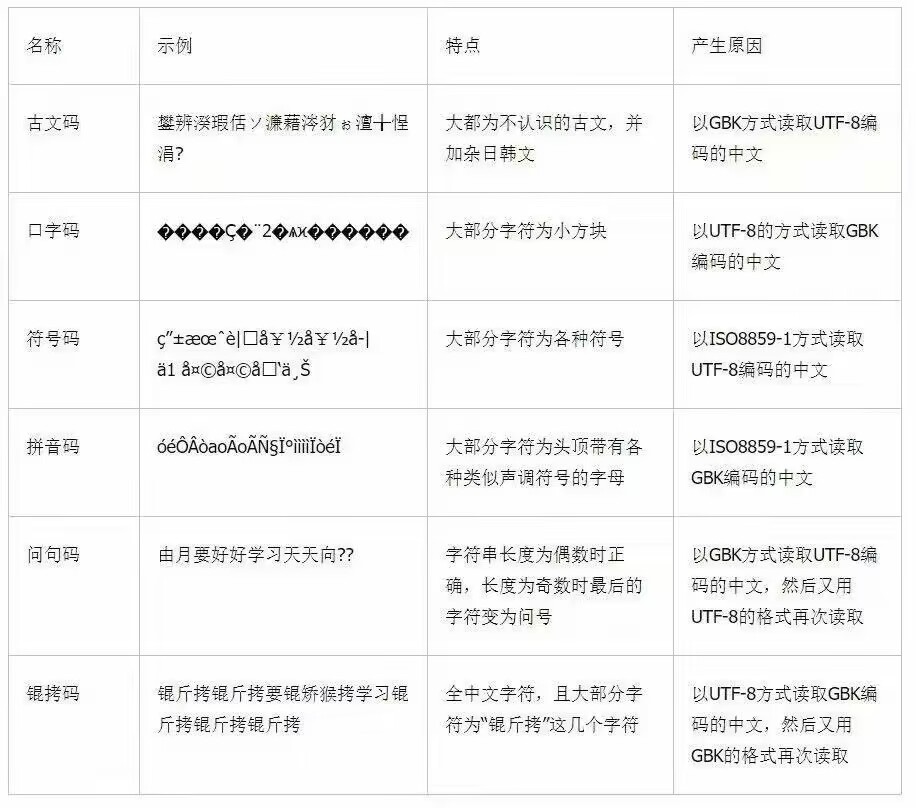
八、文件编码
1、概念
文件编码的存在在代码中十分重要,计算机的数据存储主要以二进制进行存储。编码分为很多种,现在以GBK和UTF-8为主。但是建议在敲代码的时候都要统一标准,不然会出现乱码:

2、文件的读取操作
日常中我们使用电脑的时候会对文件进行许多的操作,大概可以分成三个操作:1、打开文件 2、读写文件 3、关闭文件 那我们要如何运用在Python中呢?
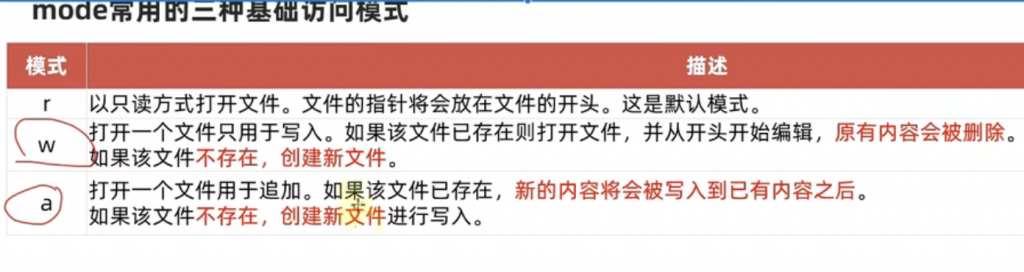
①open()函数

name的话大家都能明白,mode的话就是打开文件的一个方式,常见的就是rwa,encoding就是一个编码模式,我们前面的概念就说明白了,UTF-8用的量会比较多,所以建议直接UTF-8。
下面这张图就是用来解释 mode 的三大模式:
接下来把一个简单的文件开启给大家看看:
f = open("C:/Users/xxxxxx/Desktop/活动安排.txt","r",encoding="utf-8")
print(type(f))输出的内容如下:
<class '_io.TextIOWrapper'>②read()函数
read的话就是读取一个文件中的内容,示例代码:
print(f"{f.read(10)}")10代表的是读取10个字符。

如果说你要读取所有内容的话就是直接把10去掉 这样的话就可以把文件内的内容直接提取出来。
③readlines()函数
readlines函数其实是一个封装函数 他可以将一个文件内的内容作为列表来进行封装起来:
f = open("C:/Users/xxxxx/Desktop/11.txt","r",encoding="utf-8")
# print(type(f))
# print(f"{f.read(10)}")
readlines = f.readlines()
print(readlines)
print(type(readlines))输出的内容就是:
['真境的博客是真境搭建的\n', '运行也有几年了!']
<class 'list'>他会自己通过换行的形式进行封装,封装成列表。如果想要单独输出内容呢?请看以下代码:
lines = f.readline()
lines2 = f.readline()
lines3 = f.readline()
print(lines)
print(lines2)
print(lines3)这样的话就可以把内容按照行来一行一行的输出了。当然这个东西也可以通过循环来进行输出内容:
for i in f:
print(i)f的话应该不用解释,和上面的内容是存在联系的:引用文件。
④文件关闭
文件关闭的形式有两种,一种是直接让程序睡着:
time.sleep(50000)这是让程序睡眠的时间,单位是秒。但是你会发现程序还是处于一个占用的状态,这时候我们就可以直接使用close函数直接关闭了:
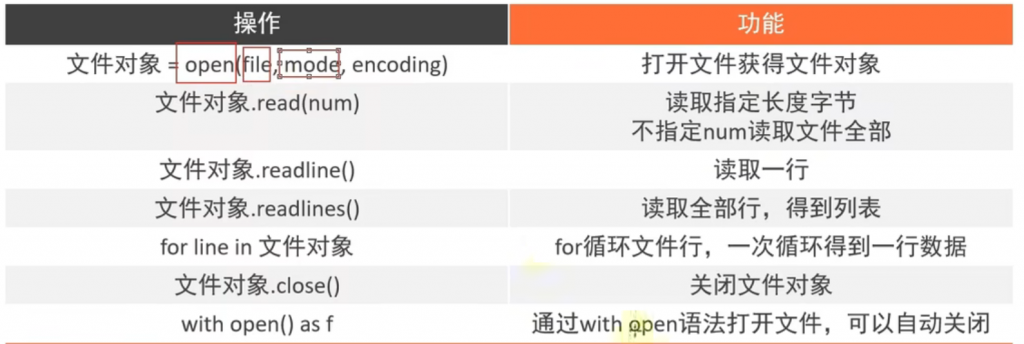
f.close()⑤with open函数
with open 函数有什么作用,他有一个差别就是当你休眠服务的时候并不会继续使用/占用你的文件,怎么理解其实可以理解成直接一口气读完文件,热插拔一样的拔出去了。示例代码:
with open("C:/Users/ZherKing/Desktop/11.txt","r",encoding="utf-8") as f:
for line in f:
print(line)
time.sleep(50000)接下来就是一个操作汇总:
⑥count函数
字面意思,就是在你一大串文本中来找某个内容有多少个。示例代码:
content = f.read()
count = content.count("真境")
print(count)但是作为列表存储的数据,你会发现存在换行符 \n 那我们可以通过前面教的 split 函数来切掉 \n:
counts = 0
for line in f:
line = line.strip()
words = line.split(" ")
for word in words:
if word == "真境":
counts += 1这样的话同时也可以使用 for 循环来对内容进行计数
3、文件的写入操作
①定义&基础操作
文件要读取的话也要写入,因此我也要交给大家如何将内容写入在文本文档中。和前面的意义,我们需要打开文件,但是和上面的读写不一样的是,他需要的是读取。查看代码:
import time
f = open("C:/Users/XXXXX/Desktop/test.txt","w",encoding="utf-8")
f.write("Hello!!!")
f.flush()
time.sleep(600000)示例代码中将刚刚上述的内容的read改成了write。然后不一样的是我们调用了write函数来进行写入内容“Hello!!!”,然后再用了下flush函数来进行刷新,这个flush函数到底有上面用,就是将写入内容确定下来,后直接刷新确认写入。所以说建议一口气将需要写入的内容都准备好了,再刷新。否则会增加一个写入量。
另外,想特别说的一个功能就是 test.txt 这个文件即使不在的话,他也会给你创建!当然保存文件也可以是另一种形式 就是用 close() 函数,这样的话就可以保存你写入的内容了。
4、文件的追加操作
文件追加是什么?就是在原来文件的写入操作上再加入一些东西,示例代码:
f = open("C:/Users/xxxx/Desktop/test.txt","a",encoding="utf-8")
f.write("快来!")
f.close()这样的话就可以追加一个写入操作了。如果你需要换行写入的话就在文本内容添加个 \n 就可以了。

5、综合案例 – 需求分析


直接公布答案:
fr = open("C:/Users/xxxx/Desktop/test.txt","r",encoding="utf-8")
fw = open("C:/Users/xxxx/Desktop/test.txt.bak","w",encoding="utf-8")
for line in fr:
line = line.strip()
if line.split(",")[4] == "测试":
continue
fw.write(line)
fw.write("\n")
fr.close()
fw.close()解释的话应该不需要解释,这些东西都是咱们讲过的内容就是了,另外附上附件,免得你们自己打:
周接伦,2022-01-01,100000,消费,正式
周接伦,2022-01-01,100000,消费,测试九、文件异常
1、概念
其实文件异常这种东西不需要怎么多解释,非要解释就是BUG嘛(漏洞),在Python中的话文件异常的触发方式就是我们上面进行文件的读取操作,如果被读取的文件不存在的话,不就是异常了嘛。

2、捕获异常
当程序出现错误的时候我们需要进行异常的捕获,这样的话我们才知道代码错在哪里,为什么会错了。如果代码出错了,我们是否有一个应对的措施?接下来看示例代码:
try:
open("C:/Users/ZherKing/Desktop/test1.txt","r",encoding="utf-8")
except:
print("出现异常!读取文件编程了写入模式")
open("C:/Users/ZherKing/Desktop/test1.txt", "w", encoding="utf-8")try的话其实就是就是尝试一个可能出现错误的内容进行尝试,那如果是真的错误的话就会进行运行 except中的内容。
3、捕获指定异常
Python的话肯定不止只有一两个异常啦,肯定会分成很多种很多种异常的。在我们做成软件的时候肯定说要知道错误在哪里,你总不能和别人说:程序出现错误。这种东西吧,那我们如何来捕获指定的错误呢?请看示例代码:
try:
print(name)
except NameError as e:
print("出现了变量未定义的异常")
print(e)示例代码中我们故意输出变量name的内容,由于说我们并没有进行定义变量name到底是什么内容,因此我们需要进行对指定异常的捕获,像这种未定义异常的一个学名就是叫做NameError然后通过as来将错误代码直接赋值在e上,这样的话我们可以通过print语句将具体的错误给输出出来。输出内容如下:
出现了变量未定义的异常
name 'name' is not defined这样就更方便的向用户,向开发者来具体的展现错误了。
4、捕获多个异常
总不能指获取一个错误吧,你肯定不止会产生一个错误吧,是吧,那我们需要进行捕获更多的异常,请看示例代码:
try:
print(name)
1/0
except (NameError,ZeroDivisionError) as e:
print("出现了变量未定义的异常 或者 1 / 0 的一个异常错误")
print(e)如果说出现了变量名错误和0作为除数的错误,就会输出这些内容,将错误的一个学名通过元组括起来即可。
5、捕获全部异常
多个异常一个一个敲太麻烦了,干嘛不一次性全部代替出来啊?接下来就可以看示例代码:
try:
print(name)
except Exception as e:
print(e)
print("出现了未知错误")直接使用Exception概括了所有的错误代码,这不是更轻松了嘛。
6、else和finally函数的使用
①else的使用方法
当我们 try 这个代码块运行可以成功的话,那我们肯定要继续运行程序啊,那else在这边就起到了作用,请看示例代码:
name = 123
try:
print(name)
except Exception as e:
print(e)
print("出现了未知错误")
else:
print("代码没有错误")我们重新定义了下name这个变量,当try中的条件允许的话,我们就可以开始运行else函数中的代码块了。同时try的内容也会一起执行。
②finally的使用办法
finally的函数使用就是建立于,无论这个代码能不能执行,finally这个函数的内容都必须执行,如何使用请看示例代码:
name = 123
try:
print(name)
except Exception as e:
print(e)
print("出现了未知错误")
else:
print("代码没有错误")
finally:
print("程序结束!")也就是说当我们程序正确,会输出name这个变量并且执行else函数中的代码块,然后输出“程序结束”这个东西。如果说程序错误的话我们就会输出未知错误的这个程序并且输出“程序结束”这个内容。
然后放上黑马程序员的一个总结内容:

7、异常的传递性
异常可以进行传递,怎么个传递法就是用函数进行传递,通过定义一个函数后进行判断错误后比较:
def fun():
1 / 0
print(name)
def main():
try:
fun()
except Exception as e:
print(e)
main()我们通过函数的引用 将错误引用在捕获错误的函数中,这样的话可以直接把错误直接展示出来更加的方便。
十、Python的模块
1、模块的导入与运用
①导入

这是什么?这是一个黑马程序员给Python模块的一个介绍。那我们如何进行导入模块呢?请看例子:
import time
time.sleep(1)就比如说这个例子 我们通过 import 的语句来导入了 time模块,接着使用了 time 模块中的sleep语句使程序睡眠了1秒。这样的话就是等于将time的所有内容导入了,如果我只需要单单导入一个sleep语句呢?请看示例代码:
from time import sleep
sleep(1)这样的话就可以将sleep从time中引用出来了。 那你肯定会说这么麻烦,谁会一个一个函数来引入啊?那你就可以看下面的例子了:
from time import *②运用
这边讲的是如何使用as语句,as语句有什么用,如果说你记不住一个函数别名的话那你就可以给他来一个备注。这样的话方便你的使用:
import time as t
t.sleep(1)这样的话 time 就被定义成了 t 这样直接引用 t 来当作time了,同时模块的函数也可以这么做:
from time import sleep as sl
sl(5)
2、自定义模块并导入
①as语句的用法
谁说只能用Python里面的模块来使用了,咱自己也可以写一个模块!我们在同一个根目录创建两个文件,一个是HelloWorld.py 还有一个就是我们今天要导入自定义模块的部分了。
import helloworld
helloworldHelloWorld.py的文件内容:
print("Hello World")这样的话就可以直接输出Hello World 这些内容了。同时也可以作出模块中的函数:
import helloworld
helloworld.Hello()HelloWorld.py的文件内容:
print("Hello World")
def Hello():
print("Hello World")这样的话就可以导入我们自己的模块中的函数了!当然注意的是我们不能让语块函数和模块函数一样。
②__main__函数的使用
诶 你会不会发现我在HelloWorld.py设置的测试输出的内容,当被引用后还是会照样显示出来呢?这时候我们就可以使用__main__函数了,请看示例代码:
def Hello():
print("Hello World")
if __name__ == '__main__':
print("123123")这是我们在HelloWorld.py中所引用的__main__ 他的原理很简单,Python函数主要是在main中执行的,但是我们今天设置了个if的语句,来设置他这个命令只能在运行HelloWorld.py的时候才会显示出来,你无论怎么导入,都是不会显示123123的。
③__all__函数的使用
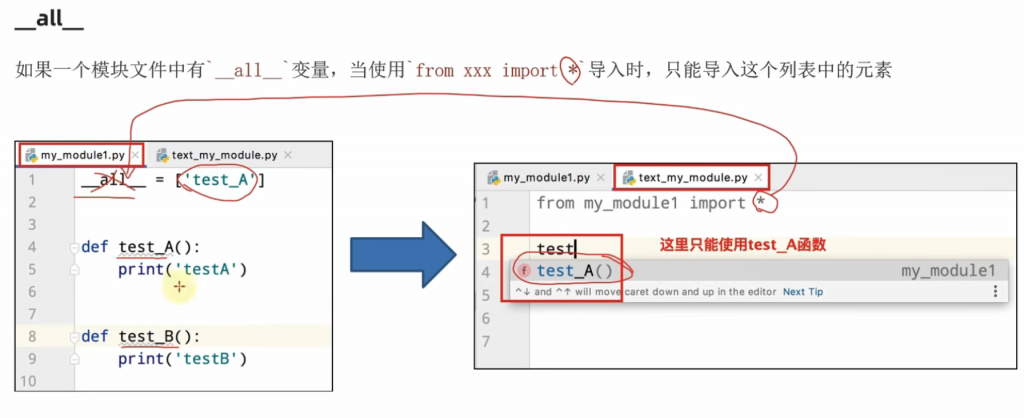
__all__函数理解的话其实很简单,就是假设我导入另一个py文件中有很多的函数块,那我只允许说使用A模块怎么办,那我们就可以使用__all__函数来进行,只有在__all__中出现的函数才能被调用。这个办法仅局限于你使用 import * 的时候才能用,那你如果是手动 from inport 导入的话还是照样可以突破 __all__ 的限制来进行使用函数块。

十、Python的包
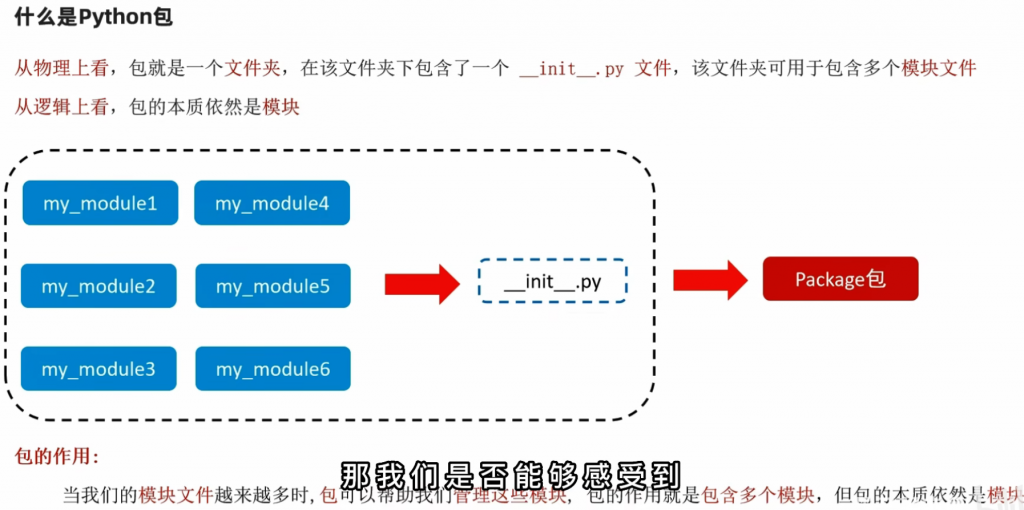
其实的话包这个东西也是很好理解的,就是你会发现你每次导入模块感觉都很麻烦是吧,那包就是让你将所有的模块打包成一快,一起引入。
1、包的引用
那都说到这里了 我们要怎么引用这个包呢?还是怎么导入这个包呢?以PyCharm为例子,我们创建一个包文件。
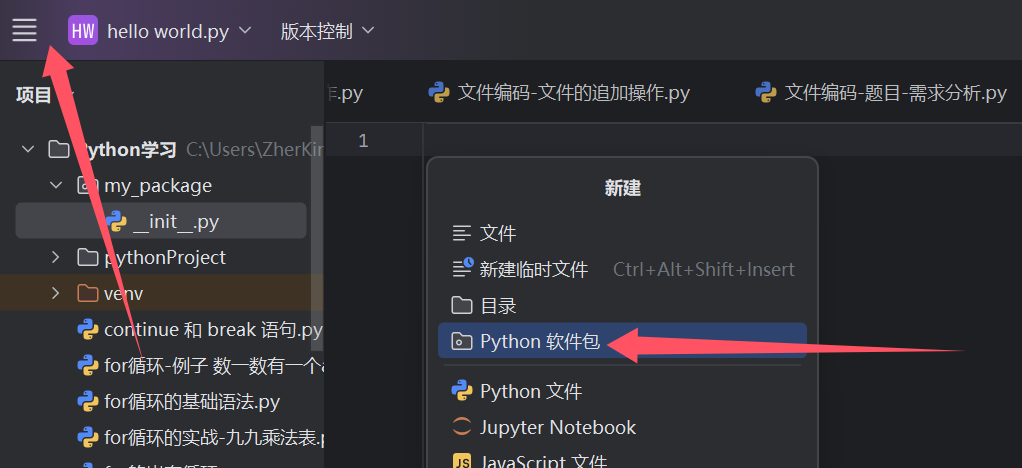
通过图上的方式,以新建的形式来创造一个Python的软件包。
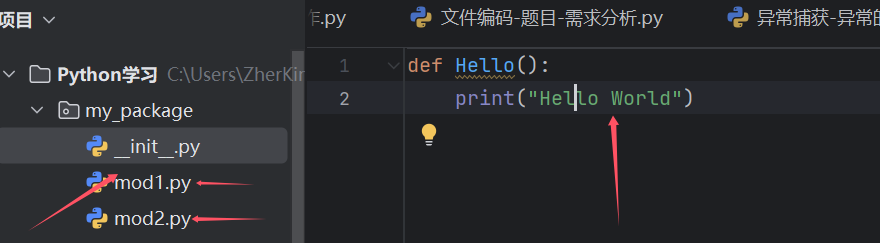
然后接下来的话我们就可以创建各种包,这样的话也方便我们的导入和使用,如何使用呢?请看示例代码:
from my_package.mod1 import Hello
Hello()这样的话就可以将我们Hello这个函数从 包里面的模块提取出来了。诶 那你肯定会很好奇__int__到底是干什么用的,咋还没从头到尾提过呢?那我可以实实在在的和你说,如果没有__int__这个文件的话,那你这个包根本不算包,另外的话 这个__int__也可以使用__all__这个函数来限制使用的范围。
不过不一样的是 前面说的是禁用函数,这边禁用的就是一整个模块了。

2、使用第三方的包
什么叫做第三方的包?那我就给大家展示下黑马程序员对他的一个解释吧:

如何安装第三方的包呢?我们可以通过pip命令来进行下载,打开cmd输入以下命令:
pip install numpy
这个是示例安装 numpy 这个第三方模块,安装成功会这样显示:

由于说Python这个下载镜像站在海外,可能下载速度慢点,我们就可以使用国内的镜像站了:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy用的是清华大学镜像站,你会发现速度确实好了不少。那如何应用在PyCharm呢?其实PyCharm也可以直接下载:
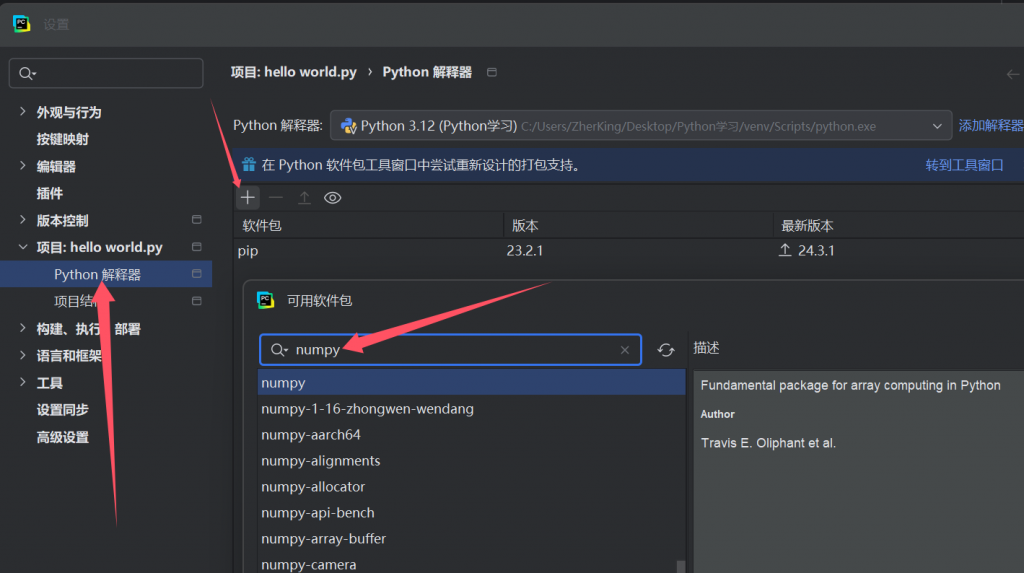
然后这样这样就可以直接安装numpy了( 前提是必须下载而不是直接使用import盲目导入。
2、题目案例
题目的话就是包括我们前面的包啊,函数啊,模块这些内容的一个整合,题目:

答案:
str_util.py:
def str_reverse(s):
return s[::-1]
def substr(s,x,y):
return s[x,y]file_util.py
def print_file_info(file_name):
f = None
try:
f = open(file_name, 'r',encoding='utf-8')
except FileNotFoundError:
print("文件捕获失败!")
finally:
if f:
f.close()
def append_to_file(file_name,data):
f = open(file_name, 'a', encoding='utf-8')
f.write(data)
f.close()具体的内容就不多说了。
十一、数据处理与使用
1、json是什么?

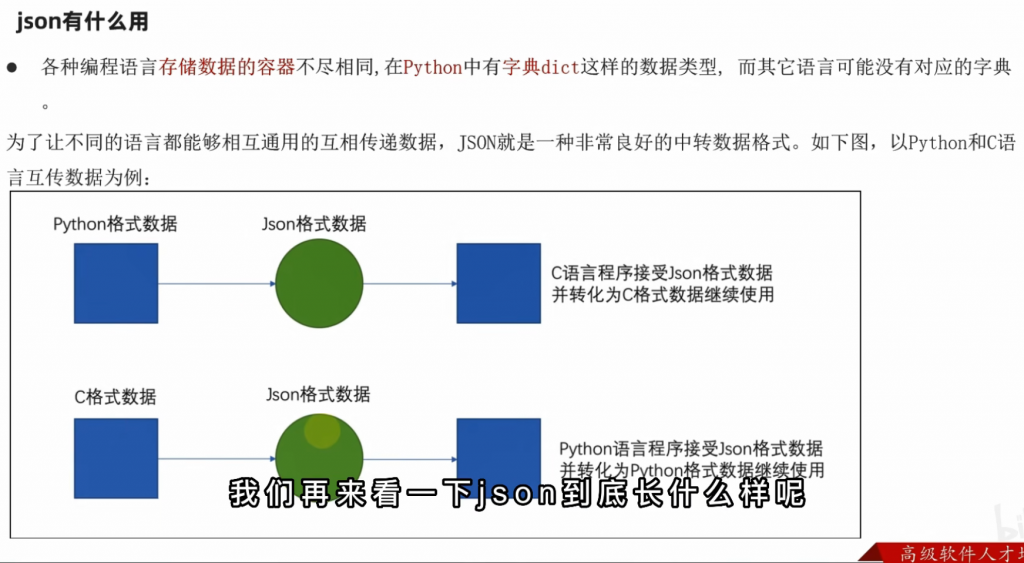
json的格式是什么?请看下面例子:
{"name":"admin","age":18}诶,咋这么像字典啊?对啊 就差不多是个字典。也可以是这样子:
[{"name":"admin","age":18},{"name":"root","age":16}]是吧 很像列表吧。
2、如何使用和导入json呢?
①将Python数据转换为json数据
如何将Python的数据转换为json数据呢?请看示例代码:
import json
data = {"age":1}
data = json.dumps(data)我们要先导入一个 json 的模块,因为他不算是什么第三方的模块,所以我们可以直接导入使用。为了方便演示我们定义了一个字典并存储了数据。重点来了,通过json的dumps功能可以将Python的数据直接转换成Json的数据,并且将转换成的结果存储在data中。 但是转换的过程中你会发现这个情况:
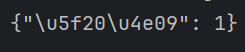
这到底啥东东?是 当使用中文的字典的时候就会出现编码错误,如何解决呢?只需要添加下面的内容即可:
data = json.dumps(data,ensure_ascii=False)②将json数据转换成Python数据
既然都说要将Python的数据转换成json的数据,那如果说转换回来呢?示例代码:
data = json.loads(data)
3、pyecharts模块
①定义+下载
pyecharts是什么?这是它的官网:pyecharts
它是一个第三方的一个模块,接下来我们看黑马程序员的一个解释:

如何安装呢?就和我们上面说的内容一样:
pip install pyecharts这样的话就可以直接下载来了。
②pyecharts快速入门
a)画一个折线统计图
from pyecharts.charts import Line
line = Line()
line.add_xaxis(["中国","美国","英国"])
line.add_yaxis("GDP",[100,200,300])
line.render()首先我们要导入一个pyecharts的一个图表类型-折线统计图
Line()的作用就是创建一个折线图的对象,然后使用add_xaxis来创建X轴的数据,反之用add_yaxis就可以绘画出Y轴的一个数据。最后用 line.render() 就可以自己生成折线图。
但是你会发现运行程序代码后什么东西都没有出现,但是如果你自习观察的话你会发现PyCharm已经给你创建了一个新的文件:

没错你的折线统计图是由html来展示出来的!运行html文件你就可以看见刚刚画的图了!
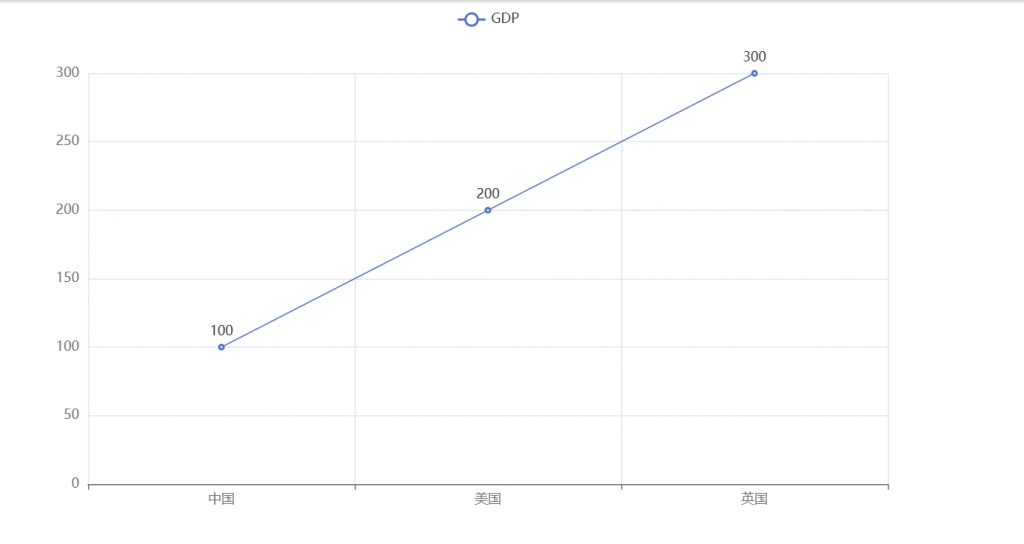
然后后面的内容其实没什么好说的了,只能说需要就搞吧。官网都给大家了自行折腾,我应该是接触不到这个东西。
十二、对象
1、定义
对象是什么?生活中需要处理大部分的数据,比如说在登记个人信息的时候,有些人会这么填写:“大家好我是真境。今年十八岁,来自中国”。在进行登记的时候这时候你就会感觉十分的臃肿,而且还不好整理信息,那我们如果拿表格来填写信息,那这些数据不是更好的处理了吗?
这就叫用对象来进行处理数据,那下面就教给大家如何处理数据!
2、用对象组织数据

解释都在上面,接下来请看示例代码:
class Student:
name = None
gender = None
nationnality = None
place = None
age = None
stu_1 = Student()
stu_1.name = "真境"
stu_1.gender = "男"
stu_1.nationnality = "中国"
stu_1.place = "福建"
stu_1.age = 18
print(stu_1.name)
print(stu_1.gender)
print(stu_1.place)
print(stu_1.age)
3、类的定义与使用
①定义
刚刚上面的代码就是给大家做了个例子,用的是类的方法,那接下来,我们将展示类是怎么用的:

②self的使用
self是什么?self是作为一个类里面的一个自变量,可以直接通过函数来直接的调取self函数的内容,请看示例代码:
class Student:
name = None
def sayHello(self):
print(f"大家好我是{self.name}")
s = Student()
s.name = "真境"
s.sayHello()大家应该大概可以看得懂代码的意思,我们定义了个变量为s 它的作用就是调取Student的一个类,然后呢向类里面传入参数name,所以说此时的name再也不是None,就是真境。那么进行传入参数了我们可以用类里面的一个函数来进行传参,这样的话我们最终的输出结果就是“大家好我是真境”
同时的话,这不只是可以引用self,当然你其他的函数也可以传参的。示例代码:
class Student:
name = None
def sayHello(self,msg):
print(f"大家好我是{self.name},{msg}")
s = Student()
s.name = "真境"
s.sayHello("你好!")我们这边self后多增加了一个新的变量 msg。那后面的大家相信能够理解

4、类与对象
什么是类与对象,现实世界的事物也有属性和行为,类也有属性和行为,使用程序中的类,可以完美的描述现实世界的事物。
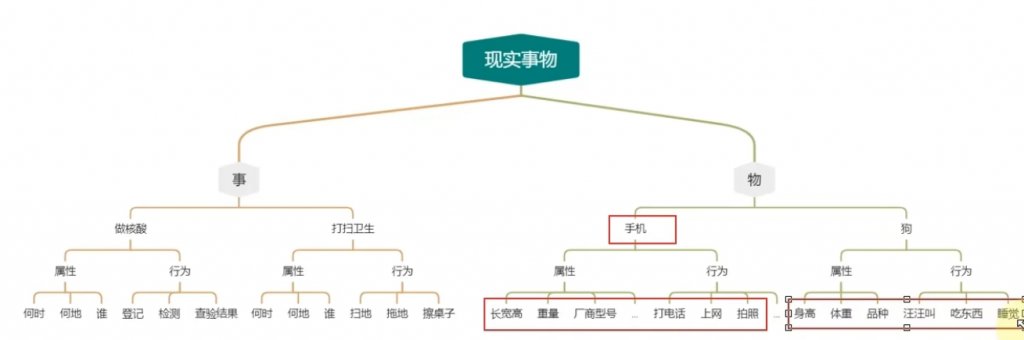
那如何理解他呢?可以通过黑马程序员的解释可以理解,比如说你一个闹钟,它有属性和行为,它的属性分成什么?型号和价格。行为呢?会响铃勒。
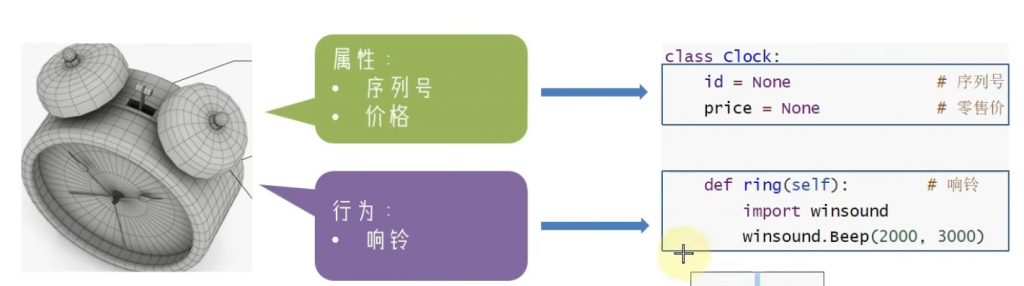
那我们根据这个特点搞了一个代码,请看示例代码:
class Clock:
id = None
price = None
def ring(self):
import winsound
winsound.Beep(500,500)
clock1 = Clock()
clock1.id = 114514
clock1.price = 20
print(f"闹钟的ID是:{clock1.id},价格是{clock1.price}")
clock1.ring()这边示例代码的话,相信大家看得懂,这边包括我们上面说的属性和行为,其中的话我们行为不是响铃嘛,我们就导入了个叫winsound的模块,频率为500,持续时间也是500。
记得记得 这玩意真的会响的,耳机党注意,另外在Linux和Mac平台是不会响的。

5、构造方法
前面我们一些类的内容,还有类的引用输出会显得比较繁琐,那有没有方式可以更轻松的对属性赋值呢?接下来我将向大家展示构造方法:__init__()
class Student:
name = None
age = None
school = None
def __init__(self, name, age, school):
self.name = name
self.age = age
self.school = school
print("Done!")
stu1 = Student("真境","18","12345678901")
print(stu1.name)
print(stu1.age)
print(stu1.school)看!这样的话就给我们的工作量减少了很多,提升了我们工作效率。另外的话这些代码还是能够省略的:
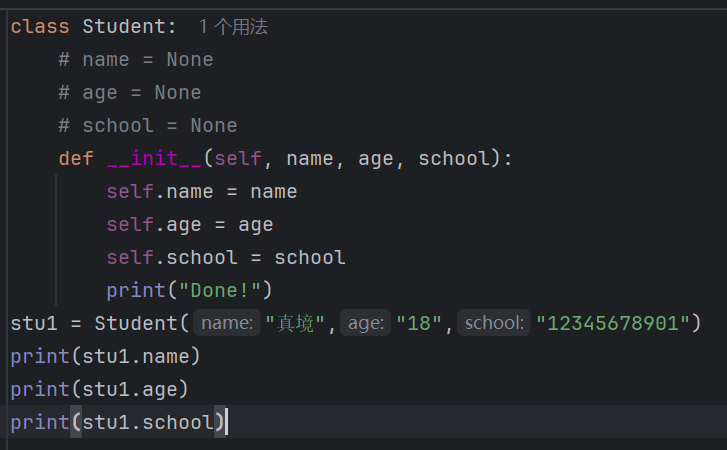
看到打注释(#)的部分了嘛,其实Python和其他语言不一样,没有说什么硬性设定一个变量的类型,因此的话这些东西都可以省略。

6、魔术方法
①定义
什么叫做魔术方法,我们上节课和大家讲解的__init__算是一种构造的方法,是Python类内置的方法之一。那我们还有一些类似于init的一些东西,他们各自都有特殊的功能:
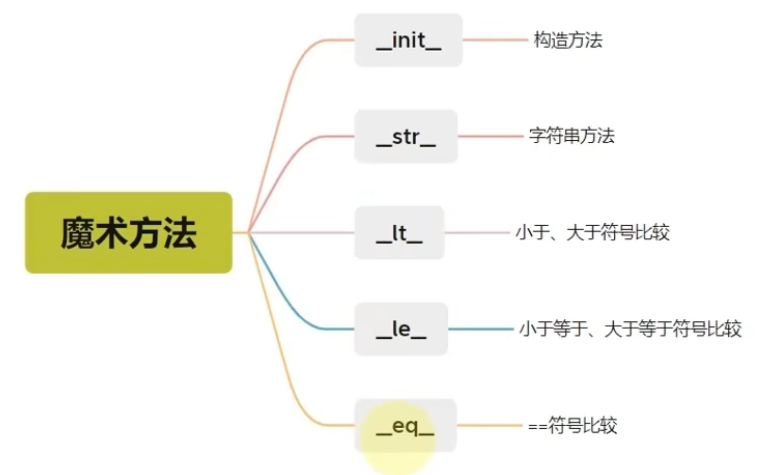
②__str__字符串方法
在学习__str__字符串的方法之前,我们先看示例代码:
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
stu = Student("周杰伦",18)
print(stu)
print(str(stu))但是输出的内容确实一群内存地址:
<__main__.Student object at 0x000001F6BDF1BD10>
<__main__.Student object at 0x000001F6BDF1BD10>为什么会输出这些内容呢?B站弹幕上看到的内容,我搬过来了:其实可以理解为(我觉得),类对象一开始并没有定义直接打印时返回的值 但使用了str后,认为定义为打印结果和str类型一样,就是认为定义了打印输出的内容 在没定义前默认返回内存地址(告诉你存在这个对象)
这时候我们就开始使用 __str__ 字符串来进行操作:
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f"age:{self.age}name:{self.name}"
stu = Student("周杰伦",18)
print(stu)
print(str(stu))按照我的理解的话大概是:当我们需要进行对类的对象变成字符串,那我们需要进行调用 str 的函数,如果没有调用的话默认输出的结果就是内存地址。
③__lt__小于符号比较方法
如果我们需要在两个对象之间进行比较,用<和>肯定是不可以的,因此的话我们需要用上__lt__的方法:
class Student1:
def __init__(self, name, age):
self.name = name
self.age = age
def __lt__(self, other):
return self.age < other.age
stu1 = Student1("真境",19)
stu2 = Student1("真境哟",22)
print(stu1 < stu2)我们新增加了个lt的用法,然后我们后面的输出,如果符合条件输出的结果是True 不符合就是False
④__le__小于等于比较符号方法
其实也是和我们上面说的lt也是有点相似的,丢个代码大家看看:
class Student2:
def __init__(self, name, age):
self.name = name
self.age = age
def __le__(self, other):
return self.age <= other.age
stu3 = Student2("真境",19)
stu4 = Student2("真境哟",19)
print(stu3 <= stu4)⑤__eq__比较运算符的实现方法
也是一样的道理,就放个代码给大家看吧:
class Student3:
def __init__(self, name, age):
self.name = name
self.age = age
def __eq__(self, other):
return self.age == other.age
stu5 = Student3("真境",19)
stu6 = Student3("真境哟",22)
print(stu5 == stu6)
7、封装
①概念与了解
封装是什么?就像我们前面说的闹钟一样,可以将属性和行为封装起来:
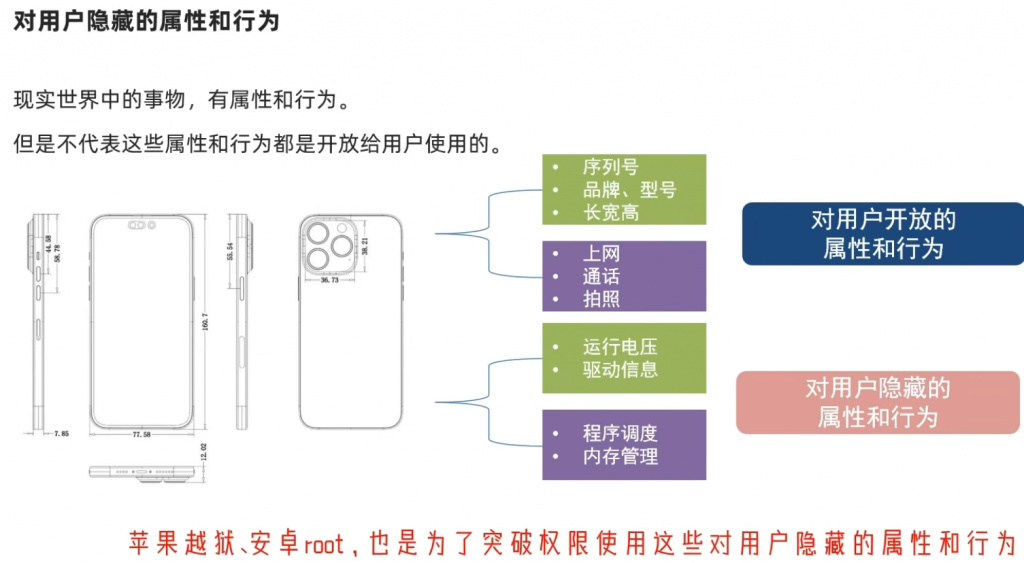
那我们接下来就看示例代码:
class iPhone:
IMEI = None
producer = None
__current_voltage = None
def call_by_5g(self):
print("5G Start!")
def __keep_single_core(self):
print("use the single core to saving the battery")
phone = iPhone()
phone.__keep_single_core()
phone.__current_voltage其中呢 __开头的函数就是一个隐形函数,也就是封装.即使你通过下面的调用也是无效的,只会报错 这就是一个简单的封装方式. 但是的话在函数内部的话是可以进行识别并且运行的:
class iPhone:
IMEI = None
producer = None
__current_voltage = 1
def __keep_single_core(self):
print("use the single core to saving the battery")
def call_by_5g(self):
if self.__current_voltage >= 1:
print("5G Start!")
else:
self.__keep_single_core()
phone = iPhone()
phone.call_by_5g()函数调用就看示例代码中的例子,都是处于一个self的情况下运行,所以可以成功的调用.

②题目

直接给大家放出答案:
class iPhone:
__is_5g_enable = False
def __check_5g(self):
if self.__is_5g_enable == True:
print("5G is enable!")
else:
print("5G is disable!using 4G network now!")
def call_by_5g(self):
self.__check_5g()
print("is calling!")
phone = iPhone()
phone.call_by_5g()8、继承
①基础语法
继承是什么东西?就是某一串代码,要进行更新,他不是从0开始写,而是继承了原先的代码,在此基础上延续更新:
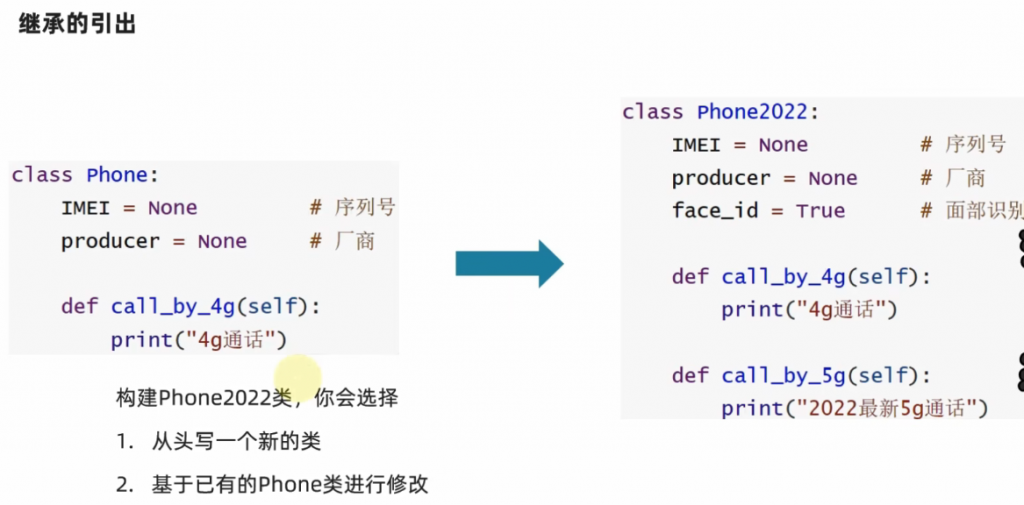
那如何通过Python代码来进行继承呢?请看示例代码:
class phone:
IMEI = None
producer = None
def call_by_4g(self):
print("4G Calling")
class newphone(phone):
FaceID = None
def call_by_5G(self):
print("5G Calling")
phone = newphone()
newphone.call_by_5G(1)其中呢 我们的类newphone,就是继承了老的类 phone,继承的用法就像:

那如果要多次继承过个父类名呢?请看示例代码:
class phone:
IMEI = None
producer = None
def call_by_4g(self):
print("4G Calling")
class newphone:
FaceID = None
def call_by_5G(self):
print("5G Calling")
# phone = newphone()
# newphone.call_by_5G(1)
class newphone1:
NFC = None
def use_the_NFC(self):
print("NFC is enable!")
def aphone(newphone,newphone1,phone):
pass后面的aphone这个函数的话就是用来继承的,由于python强制说def函数的话必须要有语句块在内,那我们只能用pass来替代,pass在这里什么作用都没有就是一个替代的作用。
②复用父类
什么叫做复用父类?就相当于重写,比如说你今天手机生产的厂商是A,明天想换到B,那这个办法就是一个重写的方式。接下来看示例代码:
class phone:
IMEI = "ZhenJing"
def call_by_5G(self):
print("This is a 5G call!")
class newphone:
IMEI = "ZhenJingYO"
def call_by_5G(self):
print("This is a 5G call!")
print("is more efficiency!")
Phone = newphone()
newphone.call_by_5G(1)
print(Phone.IMEI)看到示例代码的话相比大家也看得懂,接下来给大家看输出的内容:
This is a 5G call!
is more efficiency!
ZhenJingYO是的 没错我们新的类newphone是成功的继承了原先的类phone,你会发现我们之前的IMEI是zhenjing来着但是通过这次的重写父类后你会发现成功的变成了zhenjingyo。

那我们如何调用newphone之前的父类IMEI呢?请看示例代码:
class phone:
IMEI = "ZhenJing"
def call_by_5G(self):
print("This is a 5G call!")
class newphone(phone):
IMEI = "ZhenJingYO"
def call_by_5G(self):
#方式1
print(f"父类的IMEI是:{phone.IMEI}")
print("This is a 5G call!")
print("is more efficiency!")
Phone = newphone()
newphone.call_by_5G(1)
print(Phone.IMEI)这种方法就是直接调用了上面phone类的IMEI,还有个super的方法,我不知道为什么我按照黑马程序员的敲不出来,但是我还是问了下ChatGPT:
class phone:
def __init__(self):
self.IMEI = "ZhenJing" # 将 IMEI 设置为实例属性
def call_by_5G(self):
print("This is a 5G call!")
class newphone(phone):
def __init__(self):
super().__init__() # 调用父类的初始化方法
self.IMEI = "ZhenJingYO" # 重写子类的 IMEI
def call_by_5G(self):
print(f"父类的IMEI是:{super().IMEI}") # 通过 super() 访问父类的 IMEI
print("This is a 5G call!")
super().call_by_5G() # 调用父类的方法
print("is more efficient!")
# 创建实例并调用方法
Phone = newphone()
Phone.call_by_5G() # 调用子类的方法
print(Phone.IMEI) # 打印当前对象的 IMEI我不太理解,所以先放在这里了。
九、类型注解
1、为什么我们需要类型注解?
什么叫做类型注解,就是当我们在用PyCharm进行敲代码的时候你会发现有提示:
同时在PyCharm中我们也可以进行调用(Ctrl+P):
这样的话我们可以更高效的进行敲代码,那什么叫做类型注解呢?

2、如何使用类型注解
那如何进行类型注解呢?请看示例代码:
var_1: int = 10
var_2: str = "zhenjingyo"
my_list: list[int] = [1,2,3]
my_tuple: tuple[int,str,bool] = (1,"zhenjingyo",True)我感觉没什么用,就是让你代码好看点,到时候哪里出错去哪里。我感觉打个 # 字就差不多了( 所以我们直接进入黑马程序员的总结:

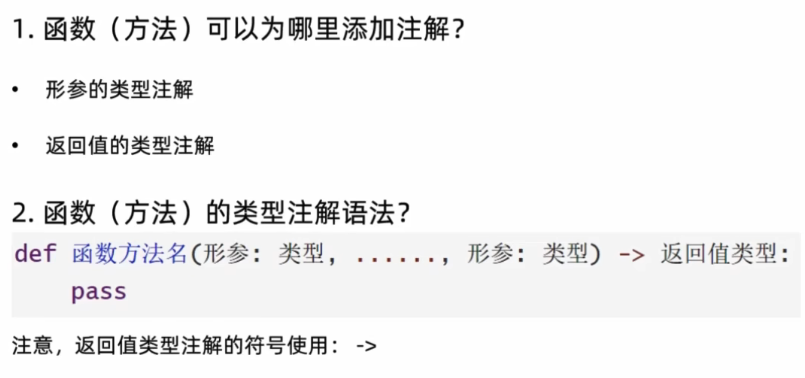
3、函数的类型注解
1、初始
类型注解其实没什么好说的就是了,直接看示例代码吧:
def func(data: list) -> list:
return data
print(func(1))我觉得注解还不如打个#(
2、Union联合类型
Union联合类型注解,在变量注解,函数方法形参和返回值的注解中,均可使用。示例代码如下:
from typing import Union
my_list: list[Union[list,str]] = [1,2,"ZhenJing"]
def func(data: Union[int,str]) -> Union[int,str]:
pass
func(1)注意:在使用Union之前要进行导包
代码的意思就是在Union[list,str]中声明了有两个类型,一个是整形,一个是字符串,就是讲这两个类型联合在一起,也是起到声明的作用吧大概。后面的话就是通过def函数来进行传入咯。来看黑马的总结吧。我估计我说不明白就是了(

3、多态
什么是多态?请看黑马程序员的解释:

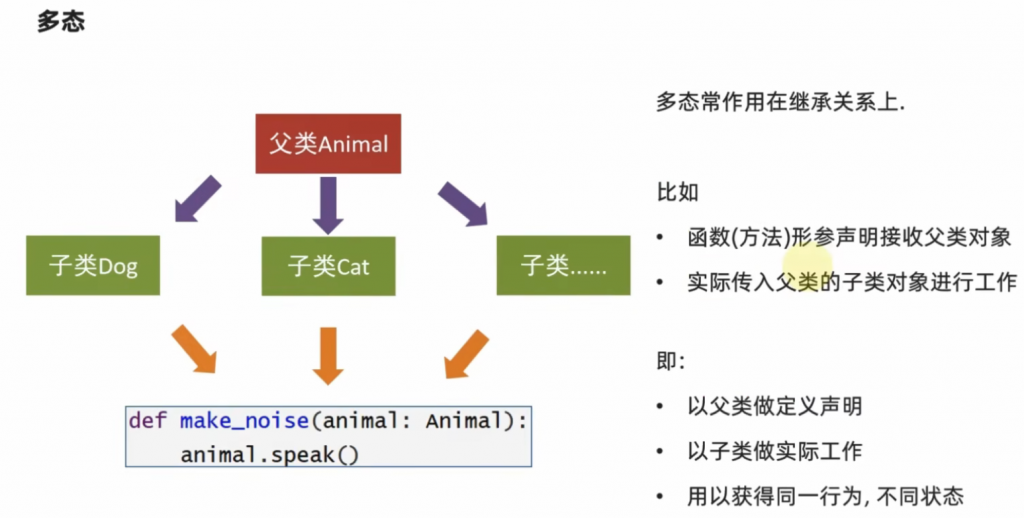
示例代码:
class Animal:
def speak(self):
pass
class Dog(Animal):
def speak(self):
print("汪汪汪!")
class Cat(Animal):
def speak(self):
print("喵喵喵!")
def make_noise(animal: Animal):
animal.speak()
dog = Dog()
cat = Cat()
make_noise(dog)
make_noise(cat)